
I modelli linguistici di grandi dimensioni vengono spesso distribuiti in produzione come sistemi statici: i loro parametri restano congelati dopo l’addestramento e ogni esperienza operativa si disperde al termine della sessione. Memento-Skills, preprint pubblicato su arXiv il 19 marzo 2026 da un team congiunto tra University College London e Hong Kong University of Science and Technology, affronta questo limite introducendo il concetto operativo di deployment-time learning — un terzo paradigma di adattamento che lascia invariati i pesi del modello e sposta l’intero processo di apprendimento su una memoria ‘esterna’: una libreria di competenze eseguibili, strutturate e auto-evolutive.
Il sistema costruisce, raffina e riorganizza autonomamente queste competenze a partire dall’esperienza operativa, attraverso un ciclo riflessivo fondato su basi teoriche formalmente dimostrate. I risultati sperimentali sui benchmark GAIA e HLE mostrano miglioramenti relativi rispettivamente del 26,2% e del 116,2% rispetto alla baseline, con una libreria che si espande in autonomia da cinque competenze atomiche iniziali fino a 235 unità organizzate in cluster semantici coerenti. Il contributo è solido nei fondamenti, onesto nei limiti dichiarati e interamente open source.
Il problema: i modelli congelati non imparano
“Lunedì mattina, ore 9:47. La macchina del caffè è rotta. J. fa il suo ingresso con un thermos di tè, scruta una parete di dashboard Grafana completamente coperte di rosso e constata l’ovvio con la frase che nessuno nel team vorrebbe sentire: “Vedo che l’agente è ancora inchiodato esattamente al 73%. Una costanza notevole, davvero. Come uno studente che prende perennemente sei”. H. ha passato il weekend a pompare risorse GPU sul problema per guadagnare un misero 0,2% in più, scambiandolo per un progresso; mentre S., ingegnere senior con dodici anni di produzione alle spalle, senza neanche alzare lo sguardo dal terminale, spegne subito gli entusiasmi dicendo: “Rientra nell’intervallo di confidenza H., hai appena bruciato 400 dollari in potenza di calcolo per non imparare assolutamente nulla.”
Questa scena inquadra con precisione un problema reale e diffuso: i Large Language Models (LLM) — sistemi neurali addestrati su enormi corpora testuali per generare e comprendere il linguaggio naturale — vengono distribuiti in produzione come entità statiche (frozen). I loro parametri, ovvero i miliardi di valori numerici nei quali è codificata la loro conoscenza iniziale, restano congelati al termine dell’addestramento. E ogni nuova conversazione, ogni errore commesso e ogni esperienza operativa svaniscono al termine della sessione.
Il paragone più calzante è quello di un medico che ogni mattina si sveglia senza alcun ricordo del giorno precedente: tecnicamente competente, ma strutturalmente incapace di migliorare sul campo. I modelli dispongono in realtà di una memoria a breve termine — la context window, ovvero la porzione di testo elaborata all’interno di una singola interazione. Ma il limite non risiede – solo – nell’assenza o nei limiti della memoria contestuale, ma nella mancanza di apprendimento persistente, ovvero la capacità di aggiornare il proprio comportamento futuro sulla base dell’esperienza passata. Questa distinzione è il punto di partenza di Memento-Skills.
Il paper introduce una terza via rispetto ai due paradigmi dominanti per l’adattamento degli LLM in tali scenari (Pre-Training e Fine-Tuning): il deployment-time learning. Un sistema nel quale i parametri del modello restano invariati, mentre l’intero processo di adattamento viene spostato su una memoria esterna capace di evolversi in modo dinamico e autonomo durante l’uso reale del sistema.
L’idea centrale: la skill come unità di memoria
“J. prende un pennarello e traccia un ciclo sulla lavagna: Read from memory. Act. Get feedback. Write to memory. Repeat. Lo chiama Read-Write Reflective Learning. H. osserva che somiglia a “un ciclo for con un vector store”. J. lo corregge: “Esatto. Ma un ciclo for con garanzie di convergenza.”
L’approccio brilla per la sua essenzialità. Invece di limitarsi a memorizzare “cosa è successo” — come farebbe un database di log o un diario di interazioni — Memento-Skills archivia il “come farlo”. Non si tratta di una raccolta passiva di episodi, ma di competenze operative strutturate e ricavate da essi. Il paper definisce queste unità come skill, marcando una distinzione netta rispetto ai comuni database di prompt.
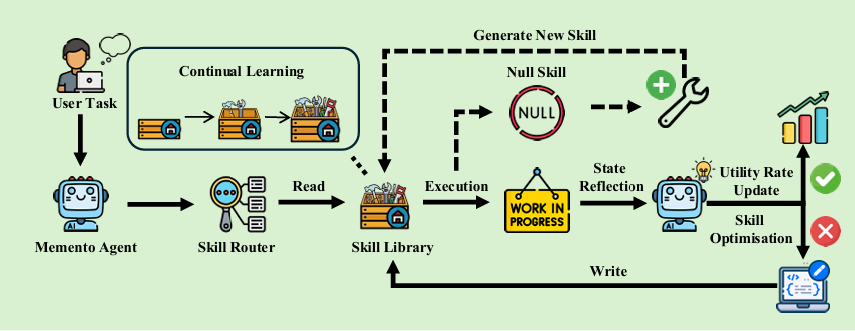
Una skill in Memento-Skills non è una stringa di testo statica. È un artefatto multi-componente strutturato come una cartella: una specifica dichiarativa in formato Markdown (SKILL.md) che descrive scopo, ambito e condizioni di applicazione, accompagnata da eventuali script eseguibili e prompt ottimizzati per il task specifico. Questo la rende eseguibile — non solo descrittiva — e modificabile in modo mirato: quando il sistema apprende dall’esperienza, non riscrive tutto, ma aggiorna esclusivamente il componente responsabile dell’errore.
Il paper attinge a un’analogia consolidata nella letteratura sul motor learning (apprendimento motorio). All’inizio, una competenza appena acquisita è fragile e circoscritta: richiede pianificazione deliberata e sforzo cognitivo elevato. Con la pratica, i percorsi neurali si consolidano e l’esecuzione diventa progressivamente automatica — trasformandosi in una sorta di memoria muscolare computazionale. Memento-Skills replica questo processo: una skill nasce grezza, viene rifinita attraverso iterazioni successive e diventa infine una routine affidabile, pronta all’uso in modo del tutto autonomo.
Skill Memory: nel framework di Memento-Skills, la Skill Memory è una collezione dinamica di artefatti riutilizzabili che funge da memoria esterna persistente per l’agente. A differenza della memoria episodica tradizionale, che si limita a registrare sequenze grezze di stati e azioni, la Skill Memory codifica direttamente le azioni in procedure operative. Ogni unità è un oggetto attivo che integra specifiche, codice e prompt, permettendo al sistema di evolvere senza mai ridursi a un semplice registro passivo di dati.
Questa libreria di competenze costituisce l’intelligenza evolutiva del sistema. Mentre il modello LLM sottostante resta congelato e invariato, è la collezione di skill — fornita come contesto al momento dell’esecuzione — a espandersi e migliorare. Il cuore teorico del sistema risiede nel meccanismo di routing: l’agente non deve recuperare il ricordo semanticamente più simile, ma la competenza che si è dimostrata comportamentalmente più efficace per risolvere il task corrente.
Come funziona: il ciclo in cinque passi
Per far questo, Memento-Skills si affida all’algoritmo di Read-Write Reflective Learning, che si articola in cinque fasi atte a scandire l’attività dell’agente per ogni compito ricevuto.
Osserva (Observe). Il sistema riceve il task e costruisce un input aumentato che combina la domanda corrente con la tip memory — una memoria di suggerimenti generici accumulati nelle interazioni precedenti. Questa integrazione permette di richiamare le lezioni già apprese direttamente nel contesto, senza consultare ogni volta l’intera libreria delle competenze.
Leggi (Read). Il router seleziona la skill più rilevante dalla libreria. A differenza dei sistemi RAG — Retrieval-Augmented Generation, architetture che combinano generazione testuale e recupero documentale — che si basano sulla similarità semantica, spesso ingannevole, il router di Memento-Skills è un modello contrastivo addestrato tramite reinforcement learning offline a un solo passo. In pratica, l’obiettivo di questa fase non è trovare il testo più simile, ma la skill comportamentalmente più utile per il successo dell’esecuzione. Se non viene trovata alcuna skill adatta, il sistema ne genera una nuova da zero a partire dal task specifico rilevato.
Esegui (Execute). L’LLM affronta il task utilizzando la skill recuperata come guida operativa. Poiché i parametri del modello sono congelati, la skill funge da unico strumento per orientarne il comportamento verso il risultato desiderato.
Riscontro (Feedback). Un giudice — un LLM configurato appositamente per la valutazione — analizza l’output rispetto alla risposta corretta e assegna un reward binario: corretto o non corretto.
Scrivi (Write). Se il task ha successo, viene aggiornato il punteggio di utilità della skill. In caso di fallimento, si attiva la failure attribution: un selettore identifica la competenza responsabile dell’errore all’interno della traccia di esecuzione, che viene riscritta per includere strategie alternative o guardrail specifici. Se l’utilità di una skill scende sotto una soglia critica, il sistema avvia la skill discovery, ristrutturando completamente la competenza o sintetizzandone una nuova.
Ogni modifica è poi protetta da un unit-test gate, con il quale il sistema genera un caso di test sintetico, verifica la skill aggiornata e la accetta nella libreria solo se supera il vaglio del giudice. In caso contrario, esegue un rollback alla versione precedente, garantendo la non-regressione sulle competenze già acquisite.
Failure Attribution: la failure attribution (attribuzione del fallimento) è un processo di credit assignment focalizzato sulle skill. Invece di registrare un fallimento come dato generico, il sistema localizza il punto esatto di guasto all’interno del flusso operativo e interviene esclusivamente su di esso. Questo approccio permette a Memento-Skills di migliorare in modo mirato e incrementale, evitando di compromettere l’intera politica decisionale per un singolo errore.
I risultati
I dati sperimentali provengono da due benchmark distinti, condotti utilizzando Gemini Flash di Google come modello LLM sottostante — un dettaglio rilevante, poiché i risultati sono legati alle capacità specifiche di quel modello e non generalizzabili a priori ad architetture diverse.
GAIA (General AI Assistants) è un benchmark composto da domande complesse basate sul mondo reale che richiedono ragionamento multi-step, navigazione web e utilizzo di strumenti. Il paper seleziona 165 domande dal validation set, suddividendole in 100 per il training e 65 per il test. Su questo set, Memento-Skills raggiunge il 66,0% di accuratezza in fase di test, contro il 52,3% della baseline Read-Write (ovvero la medesima architettura, ma priva dell’ottimizzazione a livello di skill). Il guadagno netto è di 13,7 punti percentuali, pari a un miglioramento relativo del 26,2%.3,7 punti percentuali, pari a un miglioramento relativo del 26,2%.
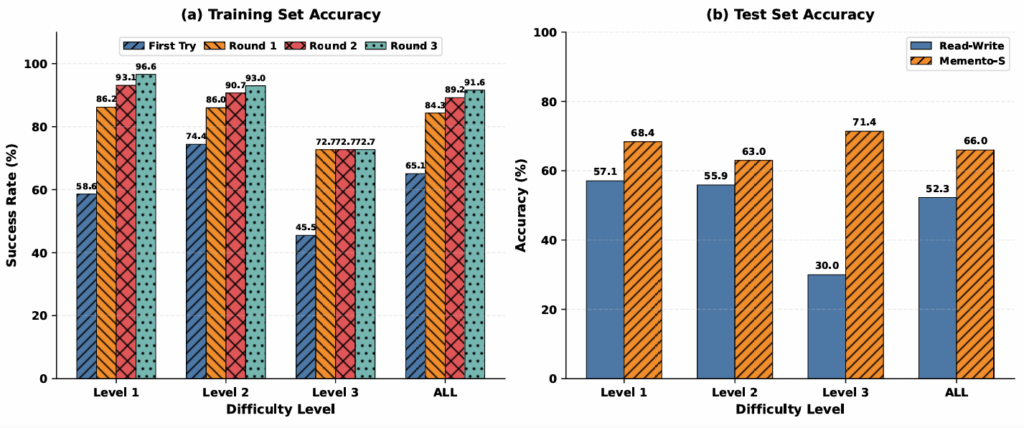
Il dato più interessante risiede però nel divario tra le prestazioni in training e quelle in test. Sul training set il sistema tocca il 91,6% di accuratezza al terzo round, mentre sul test set si ferma al 66,0%. Il paper giustifica questo scarto con estrema onestà: GAIA è strutturalmente eterogeneo. Le domande di training e di test presentano scarse sovrapposizioni nei pattern di ragionamento e una skill affinata su un problema nel training set difficilmente viene attivata dal router interno di Memento per una domanda di test che richiede una logica diversa. Chiariamo il meccanismo con un esempio.
Durante il training il sistema potrebbe costruire e ottimizzare una skill capace di recuperare un indicatore macroeconomico da una fonte istituzionale, filtrare per paese e anno ed estrarre il valore corretto. Sul test set compare invece una domanda che richiede di confrontare due aggregati regionali distinti e applicare una regola di arrotondamento: una logica di ragionamento sufficientemente diversa da non corrispondere, sul piano comportamentale, alla skill già disponibile. Il router quindi non attiva ciò che non riconosce come pertinente, vanificando il guadagno dell’ottimizzazione precedente.
Sul training set il sistema eccelle perché le skill vengono costruite su misura per quei pattern specifici. Sul test set, ogni domanda presenta combinazioni di ragionamento abbastanza nuove da non trovare corrispondenza nel repertorio. GAIA, quindi, non mette alla prova la capacità di eseguire bene ciò che si è già visto, ma quella di generalizzare le skill a logiche di ragionamento mai incontrate — e su questo fronte l’architettura mostra ancora un limite strutturale rilevante.
HLE (Humanity’s Last Exam), invece, è un benchmark organizzato in categorie disciplinari coerenti — matematica, scienze umanistiche, scienze naturali e altri cinque domini — e comprende 2.500 domande sviluppate da esperti accademici per testare i limiti del ragionamento avanzato. Il paper estrae un campione di 788 domande di training e 342 di test, bilanciate uniformemente tra le discipline.
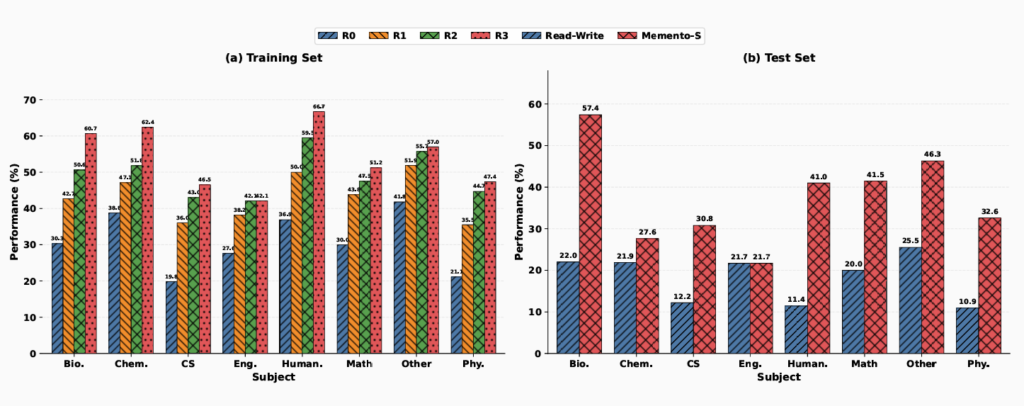
Su HLE Memento-Skills raggiunge il 38,7% di accuratezza sul test set, più che doppiando il 17,9% della baseline. Questo balzo di 20,8 punti percentuali assoluti — pari a un miglioramento relativo del 116,2% — è marcatamente superiore a quello registrato su GAIA, e la ragione risiede nella struttura del dataset. All’interno della medesima tassonomia disciplinare, una skill perfezionata su un quesito di biologia durante il training viene recuperata e riapplicata con successo su una nuova domanda di biologia in fase di test. I domini specifici condividono pattern di ragionamento abbastanza stabili da permettere il trasferimento della conoscenza. Partendo da cinque skill atomiche iniziali, la libreria si espande fino a 235 unità, le quali — come mostra la proiezione t-SNE degli embedding — si organizzano in cluster semantici ben definiti: fisica quantistica, matematica, informatica e così via.
Il confronto tra i due scenari suggerisce una conclusione che il paper esplicita in modo estremamente chiaro: l’efficacia del trasferimento di competenze dipende direttamente dall’allineamento tra la struttura del dominio affrontato e quella della libreria di skill. Non basta accumulare esperienza in modo indiscriminato: è anche necessario che l’esperienza pregressa sia strutturalmente affine ai problemi futuri. Questa non è una debolezza dell’agente in sé, ma una proprietà intrinseca del problema logico sottostante.
Vale infine la pena osservare la curva dei rendimenti decrescenti. I picchi di miglioramento si registrano nel primo round di affinamento, quando la libreria è scarsa e le skill approssimative, per poi appiattirsi progressivamente. Inoltre, man mano che lo spazio degli embedding si densifica, il raggio di copertura della memoria si restringe, riducendo al minimo sia gli errori di generalizzazione dell’LLM sia quelli di retrieval. La convergenza osservata non segnala una stagnazione del sistema, ma il raggiungimento fisiologico del suo livello operativo ottimale — un comportamento previsto dalla teoria e confermato dai dati.
Limiti, ambiguità e aspetti da verificare
Il paper si distingue per un’onestà intellettuale rara, esplicitando con trasparenza i propri limiti operativi. Gli autori dichiarano tre distinti scenari di fallimento: la qualità del retrieval offline, il successo end-to-end dell’esecuzione e la sicurezza in ambiente di produzione — la cosiddetta sandbox safety, la quale viene rimandata senza mezzi termini ai lavori futuri del team di ricercatori.
Se è vero che l’unit-test gate garantisce la non-regressione sul task specifico per il quale una o più skill sono state modificate, questo non assicura tuttavia che il comportamento complessivo del sistema rimanga prevedibile su task differenti. Una competenza iper-ottimizzata per un singolo problema potrebbe reagire in modo imprevisto di fronte a un’istruzione adiacente ma strutturalmente diversa. La skill discovery è inoltre un processo del tutto automatico: il sistema espande il proprio repertorio senza alcun intervento umano e senza una verifica esaustiva della coerenza globale della libreria. In uno scenario di deployment reale — specialmente in settori critici per sicurezza o compliance — si tratta di una dinamica da monitorare con estrema cautela.
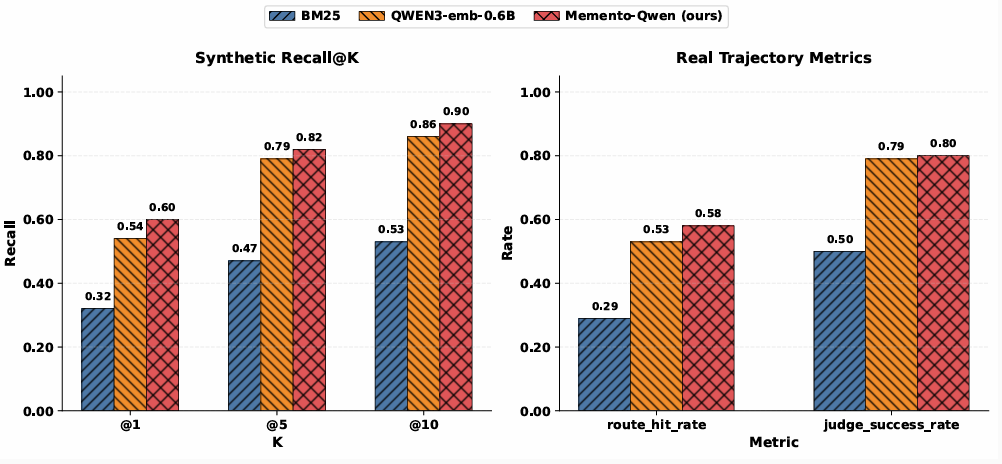
Sul fronte del router interno, il paper valuta le performance su un set di 140 query sintetiche — un campione utile ma statisticamente esiguo per trarre conclusioni definitive sulla reale generalizzazione del modello. Il Recall@1 del sistema si attesta a 0,60, superando lo 0,54 della baseline semantica e lo 0,32 del tradizionale BM25. Un guadagno tangibile, ma tutt’altro che dirompente rispetto alla baseline densa, specialmente in previsione di librerie destinate a crescere fino a migliaia di skill.
La questione della scalabilità viene lasciata deliberatamente aperta. S., l’ingegnere senior, lo fa notare nell’epilogo del paper con tagliente pragmatismo: “Cosa succede quando arriviamo a un milione di casi? Il kernel di Parzen scala?”
Il paper dimostra la convergenza effettiva su librerie di 41 e 235 skill — numeri ben lontani dalla scala industriale. Il comportamento del router contrastivo, dell’algoritmo di failure attribution e del meccanismo di skill discovery in presenza di decine di migliaia di competenze resta un territorio sperimentalmente ancora inesplorato.
Emerge infine, dalla lettura critica dell’architettura, un interrogativo che il paper non formula esplicitamente ma al quale l’impianto del sistema rimanda in modo diretto: la questione della governabilità. Un sistema che riscrive in totale autonomia le proprie procedure operative si muove in uno spazio comportamentale potenzialmente non del tutto prevedibile dai suoi stessi progettisti. Lo unit-test gate mitiga il rischio di regressione locale, ma non costituisce un meccanismo di supervisione sistemica.
La domanda — chi garantisce che le regole codificate nella libreria rimangano allineate alle intenzioni originarie di chi ha effettuato il deployment — sembra trovare nella sandbox safety, relegata a sviluppi futuri, la sua risposta. Il fatto che gli autori lo riconoscano esplicitamente è un segno notevole di maturità metodologica, ma ciò non autorizza a considerare il problema risolto.
Collocazione nello stato dell’arte
Il campo degli agenti basati su LLM si è sviluppato rapidamente lungo due linee principali. La prima è lo scaling, ovvero la creazione di modelli sempre più grandi, capaci di raggiungere prestazioni superiori per il solo effetto della dimensione. La seconda è l’augmentation, ovvero tutte quelle architetture progettate per amplificare le capacità intrinseche del modello tramite strumenti esterni, recupero di informazioni o pipeline multi-step. Memento-Skills, in tale scenario, si inserisce con una terza linea, finora meno esplorata: quella dei sistemi che apprendono dall’esperienza operativa senza crescere o mutare a livello parametrico.
Certo, non si tratta della prima proposta in questo ambito. Ad esempio, già GEPA (Genetic-Pareto Prompt Evolution), preprint del 2025, proponeva l’ottimizzazione dei prompt di sistema attraverso un ciclo riflessivo, producendo tuttavia guide esclusivamente testuali anziché skill eseguibili, ed era privo sia di un meccanismo formale di failure attribution sia di un ciclo interno di skill discovery. E Letta ha introdotto, nel dicembre 2025, un sistema di skill learning per agenti CLI capace di generare skill sotto forma di file Markdown generate a partire dalle esperienze passate. Secondo i risultati riportati nel blog tecnico di Letta, l’approccio ottiene un miglioramento relativo del 36,8% su Terminal-Bench 2.0 (un dato proveniente da documentazione esterna al paper oggetto di questa analisi e non verificabile attraverso le sole fonti primarie, nda.). In ogni caso, anche quest’ultimo approccio manca di un ciclo Read-Write riflessivo e continuo e della base teorica offerta dal framework SRDP. Infine, ProcMEM, preprint del febbraio 2026, introduce uno Skill-MDP e un meccanismo di ottimizzazione non parametrica con risultati comparabili su ALFWorld, adottando però un framing formale differente.
Memento-Skills si distingue da questi lavori per tre ragioni cumulative. Le skill sono eseguibili — non puramente descrittive — e multi-artefatto, integrando Markdown, codice e prompt in un’unica unità operativa. Vengono inoltre affinate attraverso un ciclo riflessivo continuo dotato di una failure attribution di precisione chirurgica. Infine, il sistema si fonda su un framework teorico verificabile — lo SRDP (Stateful Reflective Decision Process) — che formalizza le operazioni di lettura e scrittura della memoria e dimostra la convergenza del sistema sotto condizioni matematicamente definite. E in letteratura applicata, questa combinazione di eseguibilità, raffinamento riflessivo e fondamento formale è cosa rara.
Sul piano del routing, vale la pena segnalare il ruolo della funzione InfoNCE — una funzione di loss contrastiva, originariamente sviluppata nell’ambito del representation learning, che addestra il modello a massimizzare la similarità tra coppie positive e a minimizzarla rispetto a quelle negative — utilizzata per addestrare il router comportamentale del sistema. La scelta di InfoNCE non è casuale: la sua struttura matematica corrisponde formalmente a un passo di miglioramento della politica in un MDP a orizzonte singolo, rendendo il training del router equivalente a un’ottimizzazione offline della policy di retrieval. Questa corrispondenza è uno degli elementi teoricamente più solidi dell’intera architettura.
Il codice sorgente è inoltre completamente open source, così come l’intero catalogo delle skill. Questo livello di trasparenza è fondamentale per garantire la riproducibilità dei risultati e favorire lo sviluppo di lavori derivati, distinguendo questa ricerca dalla moltitudine di approcci analoghi confinati all’interno di ecosistemi proprietari.
Policy Iteration: nel contesto del reinforcement learning, la policy iteration è un algoritmo che alterna due fasi: la valutazione della politica corrente e il suo miglioramento verso una politica più efficace. In Memento-Skills, la fase di scrittura della skill corrisponde alla policy evaluation — si valuta il comportamento e se ne registra l’esito — mentre la fase di lettura corrisponde al policy improvement — si recupera la skill più utile per orientare il comportamento futuro. Il paper dimostra che questa corrispondenza è un’identità matematica rigorosa, non una metafora, e costituisce il contributo teorico cardine del framework SRDP (Stateful Reflective Decision Process).
Applicazioni possibili e sviluppi attesi
L’applicazione più immediata del framework riguarda gli agenti distribuiti in ambienti caratterizzati da elevata variabilità operativa e costi di fine-tuning proibitivi. Rientrano in questo scenario i sistemi di supporto tecnico costretti ad adattarsi continuamente a nuovi ticket ed errori senza poter riaddestrare il modello, gli agenti di ricerca accademica che perfezionano le proprie strategie di sintesi dominio per dominio, nonché gli assistenti alla code-review che apprendono dai pattern di errore specifici di una singola codebase.
In tutti questi contesti, Memento-Skills offre un vantaggio che né il prompting statico né il fine-tuning continuo riescono a garantire simultaneamente: un adattamento persistente a costi quasi nulli in termini di aggiornamento dei parametri.
Una prospettiva di particolare interesse è l’applicazione multi-modello. Una skill affinata da un agente governato da un modello ad alte prestazioni potrebbe essere riutilizzata da un agente basato su un modello più leggero — un processo denominabile skill-distillation — abilitando un trasferimento di competenze trasversale tra diverse famiglie di LLM. Sebbene il sistema Letta abbia già esplorato questa direzione per l’apprendimento continuo negli agenti CLI, Memento-Skills fornisce le basi formali per implementarla in modo teoricamente rigoroso.
Prima di traguardare questi sviluppi, rimane però aperto il nodo fondamentale della sandbox safety. Un sistema che genera e modifica autonomamente centinaia di skill contenenti codice eseguibile, in assenza di un meccanismo robusto di isolamento e verifica in produzione, non può dirsi pronto per il deployment in ambienti ad alta criticità. La priorità tecnica più urgente — indicata esplicitamente anche dagli stessi autori — è quella di elaborare una soluzione su questo fronte, che è anche l’oggetto dichiarato di un terzo paper della serie Memento.
Conclusione editoriale
Memento-Skills dimostra empiricamente che un sistema di intelligenza artificiale può costruire e affinare le proprie competenze operative basandosi esclusivamente sull’esperienza, senza alcuna necessità di modificare i parametri e i pesi del modello sottostante. I guadagni registrati sui due benchmark — 13,7 punti percentuali su GAIA e oltre il 116% relativo su HLE — e la capacità della libreria di espandersi in autonomia da cinque artefatti atomici a 235 competenze organizzate in cluster semantici coerenti sono evidenze pratiche di un processo di ‘specializzazione spontanea’, previsto dal framework teorico e confermato dalla geometria degli embedding alla base del sistema.
Il contributo si rivela solido nei fondamenti formali, intellettualmente onesto nel dichiarare i propri limiti e interamente trasparente nel rendere accessibili sia il codice sia i dati. Rappresenta un passo concreto verso un’idea spesso evocata in letteratura ma raramente realizzata: un agente capace di apprendere in modo analogo all’essere umano che, senza riscrivere i propri parametri, accumula e raffina progressivamente le proprie routine operative.
L’interrogativo che il paper lascia aperto non è però di natura tecnica, bensì concettuale. A che punto un sistema in grado di riscrivere autonomamente la propria libreria di competenze — operando senza supervisione umana sulle singole modifiche e impiegando una skill discovery che ne espande il repertorio secondo logiche interne — smette di essere uno strumento il cui sviluppo è interamente prevedibile dai suoi stessi progettisti? Il paper non formula esplicitamente questa domanda. Spetta a chi lo legge porsela e, soprattutto, a chi intende metterlo in produzione trovare una risposta prima di qualsiasi deployment effettivo.
Glossario
Benchmark: insieme strutturato di test standardizzati utilizzato per misurare e confrontare le prestazioni di sistemi o modelli diversi su compiti definiti. In ambito AI, costituisce lo strumento principale per la valutazione comparativa delle architetture.
BM25: algoritmo di recupero dell’informazione basato sulla frequenza dei termini e sulla lunghezza dei documenti. È un metodo sparse, ovvero opera su corrispondenze lessicali esplicite anziché su rappresentazioni vettoriali del significato. Tende a fallire quando due testi condividono lo stesso dominio ma richiedono strategie di esecuzione radicalmente diverse.
Context window: porzione di testo che un LLM è in grado di elaborare all’interno di una singola interazione. Costituisce la memoria a breve termine del modello: tutto ciò che accade al di fuori di essa non è accessibile al sistema durante quella sessione.
Contrastive learning: famiglia di tecniche di apprendimento automatico nelle quali il modello viene addestrato a ravvicinare nello spazio vettoriale le rappresentazioni di esempi simili e ad allontanare quelle di esempi dissimili. Alla base del router comportamentale di Memento-Skills.
Credit assignment: problema fondamentale nel reinforcement learning che consiste nel determinare quali azioni, tra quelle compiute in una sequenza, abbiano effettivamente contribuito a un risultato positivo o negativo. In Memento-Skills, la failure attribution risolve il credit assignment a livello di skill.
Deployment: fase di distribuzione e messa in produzione di un sistema software o di un modello AI, successiva all’addestramento e alla validazione. Il deployment-time learning è il paradigma nel quale l’adattamento avviene esclusivamente durante questa fase.
Embedding: rappresentazione numerica densa di un testo, un’immagine o un concetto in uno spazio vettoriale ad alta dimensionalità. Elementi semanticamente simili tendono a occupare regioni vicine di questo spazio. Gli embedding sono alla base dei meccanismi di retrieval e routing in Memento-Skills.
Fine-tuning: procedura di ulteriore addestramento di un modello pre-addestrato su dati specifici per un determinato dominio o compito. Modifica i parametri del modello e richiede risorse computazionali significative.
Frozen model: modello i cui parametri rimangono invariati dopo la fase di addestramento. La maggior parte degli LLM viene distribuita in questa modalità, il che impedisce qualsiasi forma di apprendimento persistente dall’esperienza operativa.
InfoNCE: funzione di loss contrastiva utilizzata per addestrare modelli di rappresentazione. Massimizza la similarità tra coppie di esempi positivi e la minimizza rispetto a esempi negativi selezionati. La sua struttura matematica corrisponde formalmente a un passo di miglioramento della politica in un processo decisionale a orizzonte singolo.
LLM (Large Language Model): modello neurale di grandi dimensioni addestrato su enormi corpora testuali per generare e comprendere il linguaggio naturale. La categoria include sistemi come GPT, Gemini, Claude e i modelli della famiglia Qwen.
Policy iteration: algoritmo del reinforcement learning che alterna la valutazione della politica corrente e il suo miglioramento iterativo verso una politica più efficace. In Memento-Skills, la lettura dalla libreria corrisponde al miglioramento della politica e la scrittura alla sua valutazione.
Pre-training: fase iniziale di addestramento di un LLM su moli enormi di dati testuali generici. Produce i parametri base del modello e richiede risorse computazionali dell’ordine di milioni di dollari.
RAG (Retrieval-Augmented Generation): architettura che combina la generazione testuale di un LLM con il recupero dinamico di documenti rilevanti da una base di conoscenza esterna. A differenza di Memento-Skills, i sistemi RAG recuperano informazioni fattuali ma non competenze operative strutturate.
Recall@K: metrica di valutazione dei sistemi di recupero dell’informazione. Misura la proporzione di casi nei quali l’elemento corretto è presente tra i primi K risultati restituiti dal sistema. Recall@1 indica la percentuale di casi nei quali il risultato corretto è il primo restituito.
Reinforcement learning (RL): paradigma di apprendimento automatico nel quale un agente impara a compiere azioni ottimali ricevendo segnali di reward dall’ambiente. In Memento-Skills, il router contrastivo viene addestrato tramite RL offline a un solo passo.
Skill discovery: meccanismo attraverso il quale Memento-Skills genera autonomamente nuove competenze quando quelle esistenti risultano insufficienti o la loro utilità scende sotto una soglia critica. Può comportare la ristrutturazione di una skill esistente o la sintesi di una interamente nuova.
Skill Memory: collezione dinamica di artefatti operativi riutilizzabili che funge da memoria esterna persistente per l’agente. A differenza della memoria episodica tradizionale, codifica direttamente le azioni in procedure operative eseguibili, composte da specifiche Markdown, codice e prompt.
SRDP (Stateful Reflective Decision Process): framework teorico introdotto nel precedente paper Memento 2 che formalizza le operazioni di lettura e scrittura della memoria in un agente LLM. Dimostra la convergenza del sistema verso una politica di retrieval ottimale sotto condizioni matematicamente definite.
t-SNE: tecnica di riduzione della dimensionalità utilizzata per visualizzare dati ad alta dimensionalità in due o tre dimensioni. In Memento-Skills, viene impiegata per rappresentare graficamente la distribuzione e l’organizzazione delle skill nello spazio degli embedding.
Unit-test gate: meccanismo di validazione automatica che verifica ogni modifica apportata a una skill prima di accettarla nella libreria. Genera un caso di test sintetico, esegue la skill aggiornata e procede all’integrazione solo in caso di esito positivo. Garantisce la non-regressione sulle competenze già acquisite.
Fonti
Paper Serie Memento — Fondamenta Teoriche
arXiv – Memento-Skills: Let Agents Design Agents
arXiv – Memento 2: Learning by Stateful Reflective Memory (Wang et al., UCL, 2025)
Lavori Comparativi
arXiv – ProcMEM: Learning Reusable Procedural Memory via Non-Parametric PPO for LLM Agents (Mi, Ma et al., 2026)
Letta Blog – Skill Learning: Bringing Continual Learning to CLI Agents
Benchmark di Valutazione
arXiv – GAIA: A Benchmark for General AI Assistants (Mialon, Fourrier et al., 2023)
arXiv – Humanity’s Last Exam (HLE)
Basi Teoriche — Contrastive Learning
arXiv – Representation Learning with Contrastive Predictive Coding (van den Oord et al., 2018)