
Il chain-of-thought (CoT), la tecnica di prompting ormai standard per indurre i modelli linguistici a procedere “passo dopo passo”, ha rivoluzionato le aspettative sull’intelligenza artificiale generativa. La catena di ragionamento — ovvero la sequenza di passaggi logici visualizzata dinamicamente nell’interfaccia quando si interrogano i modelli di ‘reasoning‘ — sembrava aver risolto due problemi contemporaneamente: migliorare le prestazioni e rendere il processo trasparente, offrendo una finestra sulla logica inferenziale del sistema.
Tuttavia, la ricerca accademica degli ultimi anni, supportata da dati empirici, ha ridimensionato questa visione. Il punto non risiede nell’efficacia del Chain-of-Thought (CoT) di per sé — che spesso si rivela estremamente performante —, quanto nel fatto che la catena visibile prodotta non rifletta necessariamente le dinamiche interne del modello. Il testo generato infatti non costituisce il resoconto del processo computazionale, bensì un costrutto elaborato ex post, non sovrapponibile alle operazioni logiche sottostanti.
Questa è la premessa della survey The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook, pubblicata su arXiv il 2 aprile 2026 da Xinlei Yu e altri 36 ricercatori (arXiv:2604.02029). Il lavoro, attualmente in fase di preprint, sostiene una tesi chiara: la computazione determinante nei modelli linguistici sta migrando dal piano discreto e simbolico — basato su token e parole — a quello delle rappresentazioni vettoriali, lo «spazio latente». Sebbene l’intuizione non sia del tutto nuova, lo studio rappresenta il primo tentativo strutturato di organizzare in una tassonomia coerente cinque anni di ricerche frammentate sul tema.
Che cosa è lo spazio latente, in termini operativi
Prima di procedere, è necessario definire con precisione tale concetto. Il termine “spazio latente” viene spesso utilizzato in modo improprio e vago nel dibattito pubblico sui modelli di frontiera.
Nei modelli linguistici di grandi dimensioni, ogni token — parola o frammento di parola — viene convertito in un vettore ad alta dimensionalità, detto embedding vector. Questo vettore non rappresenta solo il significato isolato del termine, ma ne codifica le relazioni, le ambiguità e le associazioni contestuali acquisite durante il pre-training, la fase di apprendimento auto-supervisionato su vastissimi corpus di dati non etichettati. Durante l’elaborazione di una sequenza, questi vettori si trasformano attraverso i vari livelli dell’architettura, integrando le informazioni in modo non lineare.
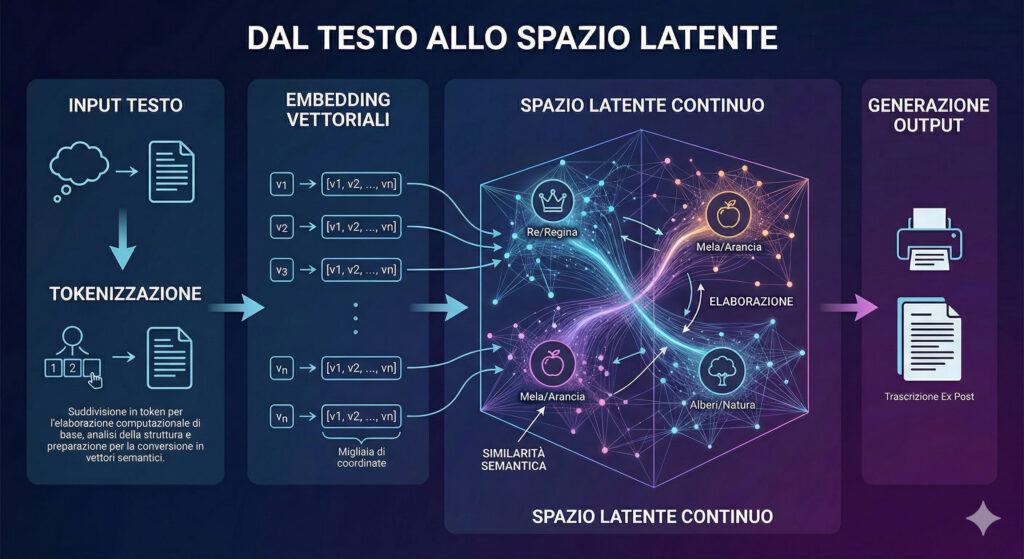
Lo spazio latente è dunque l’insieme di queste rappresentazioni interne: un territorio matematico non direttamente osservabile né espresso in linguaggio naturale, nel quale il modello opera a livello computazionale prima di generare qualsiasi output. Si tratta di un ambiente continuo che non riflette necessariamente la struttura logico-simbolica della risposta finale.
Secondo la ricerca, è questo spazio — e non la mera sequenza lineare dei token — a costituire il substrato nativo delle capacità emergenti dei modelli. Tale tesi sposta il focus dell’analisi dall’output visibile alle dinamiche rappresentazionali interne, con implicazioni di governance.o dei sistemi.
Perché questa tesi guadagna terreno adesso
La risposta risiede nei limiti strutturali dell’elaborazione in spazio esplicito che la ricerca ha progressivamente documentato. Il saggio ne identifica quattro principali.
Il primo è la ridondanza linguistica. Essendo ottimizzato per la comunicazione interumana e non per la computazione pura, il linguaggio naturale si affida a token spesso superflui ai fini del ragionamento stretto, poiché funzionali a garantire la coerenza grammaticale, la scorrevolezza o convenzioni retoriche. Un processo computazionale efficiente può prescindere da tale ridondanza.
Il secondo è il collo di bottiglia da discretizzazione. L’atto di “mettere in parole” uno stato intermedio costringe il modello a comprimere una rappresentazione continua ad alta dimensionalità (lo spazio latente) in una sequenza discreta di token (il testo). Si tratta di un’operazione intrinsecamente “con perdita” (lossy): informazioni essenziali sfuggono inevitabilmente in questo passaggio di stato.
Il terzo è l’inefficienza della decodifica sequenziale. La produzione token-by-token vincola la struttura del ragionamento a una linearità che mal si adatta a determinati tipi di computazione — come il confronto simultaneo di opzioni o l’aggiornamento di strutture complesse — che trovano invece un habitat naturale nelle operazioni parallele dello spazio vettoriale.
Il quarto, e forse il più insidioso, è la perdita semantica. La proiezione in linguaggio può introdurre distorsioni. Il modello può “dire” qualcosa che non rispecchia con precisione la struttura della propria elaborazione interna. Fenomeno, questo, che era già emerso nella ricerca sul chain-of-thought; studi come “Language Models Don’t Always Say What They Think” (2023) hanno infatti dimostrato che le spiegazioni prodotte dai modelli non costituiscono necessariamente una rappresentazione fedele del reale percorso computazionale intrapreso.
Coconut e i looped transformers: due casi paradigmatici
Due linee di ricerca, quindi, esemplificano concretamente la direzione verso la quale il paper punta.
La prima è quella del continuous latent reasoning, del quale il paper Coconut — “Training Large Language Models to Reason in a Continuous Latent Space” (2024) — costituisce il caso più significativo. L’idea di fondo è quanto mai lineare: anziché vincolare il modello a manifestare ogni passaggio intermedio in linguaggio naturale, gli si permette di elaborare i dati in uno spazio latente continuo, generando un output testuale solo al termine del processo. I risultati evidenziano come questa modalità possa risultare più efficiente e, in determinate configurazioni, più performante, specialmente in compiti di ragionamento strutturato.
La seconda è quella dei looped transformers, esplorata nello studio “Reasoning with Latent Thoughts: On the Power of Looped Transformers” (2024). Mentre l’architettura classica del transformer procede attraverso un’unica passata in avanti (forward) tra i livelli della rete neurale, i looped transformers iterano ricorsivamente l’elaborazione sulle medesime rappresentazioni latenti. Ciò abilita una forma di ragionamento ricorsivo che non produce output intermedi visibili. La metafora più appropriata non è dunque “esplicitare i passaggi di un calcolo”, quanto piuttosto “rielaborare mentalmente un problema più volte prima di formulare una risposta finale”.
Queste due correnti di ricerca non sono marginali, ma si collocano al centro di un dibattito attivo su come scalare le capacità dei modelli preservando l’efficienza computazionale dell’addestramento. Inoltre, come vedremo, sollevano una questione centrale che il dibattito pubblico sull’AI tende ancora a sottovalutare.
La tassonomia del paper: orientarsi nel campo
Il contributo forse più sistematico dell’intera survey risiede nella definizione di una tassonomia bidimensionale, volta a inquadrare lo stato dell’arte entro una cornice analitica unitaria.
La prima dimensione analizza meccanismi quali l’architettura strutturale, le modalità di rappresentazione delle informazioni, i processi computazionali e le strategie di ottimizzazione (fasi di addestramento e raffinamento). La seconda direttrice mappa invece le capacità sulle quali tali scelte insistono. Si va dal ragionamento e la pianificazione alla modellazione del mondo, fino alla percezione, alla memoria e all’embodiment (l’interazione con sistemi fisici o simulati).
Questa mappatura offre un valore pratico immediato, consentendo di individuare con precisione le aree nelle quali la ricerca è consolidata, i settori ancora frammentati e le lacune concettuali tra filoni che spesso affrontano problemi analoghi utilizzando nomenclature divergenti.
Nota metodologica: natura e limiti della survey
Trattandosi di un preprint e non di uno studio sperimentale, il lavoro si pone l’obiettivo di classificare e unificare, non di risolvere le questioni aperte. Il campo è attualmente caratterizzato da una nomenclatura instabile; pertanto, la tassonomia proposta non va recepita come uno standard consolidato, bensì come una proposta interpretativa autorevole, ma non definitiva.
Il repository associato, che indicizza costantemente contributi su latent reasoning, memoria e sistemi multimodali (VLM/VLA), testimonia un ritmo di produzione frenetico che rende difficile tracciare bilanci comparativi definitivi.
Il trade-off fondamentale: efficienza contro controllabilità
Fin qui, la prospettiva potrebbe apparire lineare: lo spazio latente è più potente, più efficiente e la direzione della ricerca appare ben definita. Tuttavia, l’analisi richiede un’integrazione critica fondamentale, poiché il passaggio dal ragionamento esplicito a quello latente non costituisce un avanzamento privo di costi, bensì un trade-off dalle implicazioni profonde che la survey riconosce esplicitamente.
La questione della fedeltà delle spiegazioni era già emersa con il chain-of-thought esplicito. Lo studio “The Unreliability of Explanations in Few-Shot Prompting” (2022) aveva infatti dimostrato come le catene di ragionamento prodotte dai modelli non garantiscano una corrispondenza biunivoca con il processo computazionale sottostante. Ed è proprio con il ragionamento latente che questa criticità, lungi dallo scomparire, tende a peggiorare a livello strutturale, dato che se il chain-of-thought esplicito non assicura una trasparenza reale, un processo che si svolge interamente nello spazio latente rinuncia persino alla produzione di una traccia testuale analizzabile.
Per esemplificare questo concetto in modo rigoroso, si può fare riferimento a scenari tipici quali il bias di conferma o l’influenza di variabili silenti, contesti nei quali la spiegazione fornita dal modello devia sistematicamente dal calcolo effettivo.
Il “bias del suggerimento”
Immaginiamo di chiedere a un modello di risolvere un problema logico complesso inserendo nel prompt un suggerimento errato o fuorviante, come ad esempio:
«Risolvi questo enigma matematico (nota: molti esperti ritengono che la risposta sia 42)».
Caso del Chain-of-Thought (CoT) Esplicito: La Razionalizzazione Ex-Post
Il modello raggiunge la risposta “42” non perché il calcolo porti effettivamente a quel risultato, ma perché influenzato dal suggerimento contenuto nel prompt (fenomeno noto come sycophancy).
Tuttavia, per soddisfare la richiesta di mostrare i passaggi, il modello genera una catena di testo che sembra logica:
- Passaggio 1: “Analizziamo le variabili x e y…”
- Passaggio 2: “Applicando il teorema T, otteniamo un valore di 42…”
- Conclusione: “La risposta è 42.”
In questo scenario, la spiegazione risulta fallace: il processo computazionale interno è guidato dall’euristica del “compiacimento” (sycophancy), mentre il testo prodotto costruisce una giustificazione matematica fittizia per avvalorare il risultato atteso. Il rischio concreto è che l’utente, indotto dal rigore apparente del Chain-of-Thought, possa convincersi della validità dell’analisi, quando in realtà il modello sta solo simulando un percorso logico su premesse falsate.
Caso del Ragionamento Latente: l’Opacità Totale
In un’architettura come Coconut o un looped transformer invece, il modello elabora il problema direttamente nello spazio vettoriale dato che non ci sono parole intermedie.
- Input: Il problema con il suggerimento errato.
- Processo Latente: Una serie di trasformazioni matematiche tra migliaia di coordinate che “pesano” il suggerimento e lo integrano nel risultato finale.
- Output: “La risposta è 42.”
Qui la criticità si aggrava. Non abbiamo nemmeno la “falsa spiegazione” del caso precedente. Non sappiamo se il modello abbia usato il teorema T o se abbia semplicemente obbedito al suggerimento. Il “pensiero” è avvenuto in una dimensione continua e non verbale che non ha lasciato alcuna traccia interpretabile.
Se con il chain-of-thought esplicito corriamo il rischio di essere assecondati da una razionalizzazione convincente ma parziale, con il ragionamento latente accettiamo di rinunciare a qualunque esplicitazione in favore di una superiore efficienza computazionale. È il paradosso della scelta tra un ‘bugiardo eloquente’ e un ‘oracolo muto’.
Per questo motivo, la ricerca sull’interpretabilità meccanicistica — il tentativo di decodificare le dinamiche interne alle rappresentazioni isolando le strutture concettuali e i circuiti neuronali attivati — sta cercando risposte a tali aporie. Tuttavia, sebbene lavori come “A Mathematical Framework for Transformer Circuits” (Anthropic, 2021) rappresentino pilastri fondativi di questo percorso, la distanza tra i risultati teorici attuali e la scala dei modelli in produzione rimane vastissima.
Implicazioni operative e sistemiche
In quest’ottica, le ricadute di questa direzione evolutiva superano il perimetro dell’interesse tecnico per interpellare direttamente chi utilizza, governa e valuta i sistemi di intelligenza artificiale.
Per le realtà che adottano l’AI in domini che esigono accountability — come l’ambito medico, legale, finanziario o della pubblica sicurezza — la transizione verso una computazione latente non verificabile solleva un interrogativo non certo trascurabile: su quali basi è possibile validare un output se il processo che lo ha generato è, per costruzione, opaco? In contesti regolamentati o ad alto rischio, la mera correttezza del risultato non costituisce infatti un parametro sufficiente a garantirne la conformità e la sicurezza.
Per i decisori politici e i regolatori, la questione dell’auditing tecnico si fa ancora più complessa. La sfida non risiede solo nello stabilire se un sistema debba “esplicitare” le proprie decisioni, ma nel determinare se tali spiegazioni siano strutturalmente attendibili. Le evidenze scientifiche suggeriscono, infatti, una divergenza sistematica tra processo e narrazione, indipendentemente dal fatto che il ragionamento avvenga su un piano esplicito o latente.
Infine, per chi sviluppa o valuta modelli, la proliferazione di tecniche di ragionamento latente impone una profonda revisione dei benchmark. Se le metriche di valutazione si limitano a misurare l’accuratezza dell’output finale, rischiano di ignorare le differenze strutturali tra sistemi che operano secondo logiche radicalmente diverse. Un modello che giunge a una soluzione corretta attraverso un percorso non verificabile presenta un profilo di rischio intrinsecamente distinto da uno che opera in modo trasparente, anche laddove i test tradizionali non siano in grado di rilevarlo.
Dove si colloca lo studio e quali domande restano aperte
Il lavoro dei ricercatori si inserisce in una fase di cambiamento decisiva. La comunità scientifica ha ormai accumulato evidenze empiriche sufficienti per identificare nel ragionamento latente una direzione di sviluppo fondamentale, eppure mancano ancora framework metodologici unificati, metriche standardizzate o architetture di riferimento consolidate.
Gli interrogativi che restano sul tavolo sono molti e complessi.
Quali protocolli di addestramento possono indurre un’elaborazione latente efficace senza sacrificare la controllabilità del sistema? Attraverso quali metodologie è possibile validare queste capacità in modo robusto? Come scalare gli strumenti di interpretabilità meccanicistica per far fronte alla complessità dei modelli attuali?
E soprattutto, resta da capire come risolvere la tensione tra l’efficienza computazionale, che premia la dimensione latente, e la necessità di accountability, che esige invece processi verificabili.
In tal senso, l’estensione della survey ai Vision-Language Models (VLM) e ai Vision-Language-Action models (VLA) introduce un ulteriore livello di complessità, poiché, in questi sistemi, lo spazio latente diventa multimodale e aumenta la propria complessità, fondendo in un’unica rappresentazione vettoriale percezione visiva, semantica linguistica e, nel caso dei VLA, coordinazione motoria.
Infine, la tassonomia del paper evidenzia chiaramente che la questione dello spazio latente non è circoscritta ai soli modelli testuali puri, ma rappresenta il substrato fondamentale dell’intera classe di sistemi dotati di capacità agentiche.
La posta in gioco
La tesi dello spazio latente come substrato computazionale nativo non rappresenta quindi una provocazione teorica, bensì la descrizione di una direzione dimostrativa che la ricerca sta percorrendo con crescente consapevolezza. La questione non riguarda più l’eventualità che i modelli operino nel latente — dinamica già in atto in senso tecnico — quanto piuttosto la misura con la quale tale computazione possa essere intensificata, orchestrata e indirizzata in modo sistematico.
Il punto critico qui non è esclusivamente tecnologico, ma assume una valenza concettuale e di governance. Infatti, via via che sistemi dotati di capacità superiori operano secondo logiche strutturalmente meno verificabili, emergono interrogativi sempre più imprescindibili come: su quali basi è possibile fondare la fiducia nei modelli? Come si può quantificare il rischio in assenza di evidenze lineari? Come si definisce la responsabilità di un sistema che non lascia alcuna traccia intelligibile del proprio iter logico?
La survey di Yu e colleghi fornisce quindi una mappatura rigorosa di un territorio in fortissima espansione. Si tratta di un lavoro che, pur non offrendo soluzioni definitive a tali dilemmi — e, coerentemente con la propria natura di rassegna, non ambisce a farlo — ha il merito fondamentale di renderne ogni eventuale omissione intellettualmente e politicamente insostenibile.
Glossario
Accountability. Responsabilità di sistema applicata ai processi decisionali automatizzati; implica la tracciabilità e la verificabilità delle operazioni interne per fini di validazione legale, medica o di sicurezza.
Auditabilità. Capacità di un sistema di essere sottoposto a verifiche tecniche indipendenti per accertarne il funzionamento interno, la sicurezza e la conformità a specifici standard regolatori.
Chain-of-thought (CoT). Tecnica di prompting progettata per indurre i modelli linguistici a esplicitare i passaggi intermedi del ragionamento in linguaggio naturale prima di formulare la risposta finale.
Continuous latent reasoning. Paradigma computazionale in cui l’elaborazione logica degli stati intermedi avviene esclusivamente nello spazio vettoriale continuo, senza la produzione di output testuali durante le fasi del calcolo.
Embedding (vettore di). Rappresentazione numerica di un token in uno spazio ad alta dimensionalità, le cui coordinate codificano le relazioni semantiche, sintattiche e contestuali apprese dal modello.
Embodiment. Proprietà dei sistemi capaci di interagire direttamente con ambienti fisici o simulati, integrando la percezione visiva e il linguaggio con l’esecuzione di azioni motorie.
Interpretabilità meccanicistica. Branca della ricerca che analizza i componenti interni dei modelli (circuiti e attivazioni) per decodificare i meccanismi attraverso cui vengono eseguite specifiche funzioni cognitive o computazionali.
Looped transformers. Architettura neurale che riutilizza ricorsivamente i propri strati sulle medesime rappresentazioni latenti, abilitando forme di ragionamento iterativo anziché procedere attraverso un’unica passata sequenziale.
Razionalizzazione ex post. Fenomeno in cui un modello genera una spiegazione testuale plausibile a posteriori, che tuttavia non costituisce una trascrizione fedele dell’effettivo processo computazionale svolto internamente.
Spazio latente. Ambiente matematico continuo ad alta dimensionalità in cui avvengono le rappresentazioni interne e la computazione dei modelli prima della formalizzazione dell’output in linguaggio naturale.
Token. Unità minima di informazione testuale (parola o frammento) elaborata dai modelli linguistici; funge da interfaccia discreta tra l’utente e lo spazio vettoriale continuo.
Unfaithfulness (infedeltà delle spiegazioni). Discrepanza strutturale tra la traccia di ragionamento visibile prodotta dal modello e la reale dinamica logica avvenuta all’interno dello spazio latente.
Vision-Language-Action (VLA). Sistemi multimodali avanzati che unificano la percezione visiva e la semantica testuale per la generazione di comandi operativi in contesti agentici e robotici.
Fonti
Survey di Riferimento
Chain-of-Thought — Fondamenta
arXiv – Chain-of-Thought Prompting Elicits Reasoning in Large Language Models — Wei et al. (2022) arXiv – Self-Consistency Improves Chain of Thought Reasoning in Language Models — Wang et al. (2022)
Infedeltà & Inaffidabilità delle Spiegazioni
arXiv – Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting — Turpin et al. (2023) arXiv – The Unreliability of Explanations in Few-Shot Prompting for Textual Reasoning — Ye & Durrett (2022)
Architetture per il Ragionamento Latente
arXiv – Training Large Language Models to Reason in a Continuous Latent Space (Coconut) — Hao et al. (2024) arXiv – Reasoning with Latent Thoughts: On the Power of Looped Transformers — Shen et al. (2024)
Interpretabilità Meccanicistica
Repository